











热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A


正则表达式编程
接下来我们会看到更多的示例。同时,也会看到C++正则表达式API的更多功能。 为了便于下文示例的讲解,我们以维基百科上对于正则表达式的介绍文本为基础。
我们将这段文字保存在名称为content.txt的文本文件中。下面几个示例会在这个文本上操作。
在上文中,为了从字符串中查找出所有匹配的字符,我们的做法是遍历原始字符串的每一个子字符串来进行查找,这样做很明显效率很低。更好的做法当然是使用迭代器。

在一大段文本中查找所有匹配的目标,这是一个非常常见的需求。而迭代器正好满足这一需求,它会依次返回它从文本中找到的匹配内容。

这段代码的说明如下:
ifstream读取文本文件 这段代码输出如下:

接下来的几个代码示例的主体结构和这里会很相似,我们总是先打开文本文件,然后读取每一行来进行处理。
前面的示例中我们已经看到,通过std::regex并传递字符串就可以构造正则表达式对象。实际上,除了std::regex,还有宽字符版本的std::wregex。它们都源自std::basic_regex

在创建正则表达式对象的时候,除了描述规则本身的字符串之外,还可以传递一个flag_type类型的参数,该参数的值定义在std::regex_constants::syntax_option_type中。它们中与“文法”相关的已经在上文介绍过了。

这其中,第一个是我们最常用的。
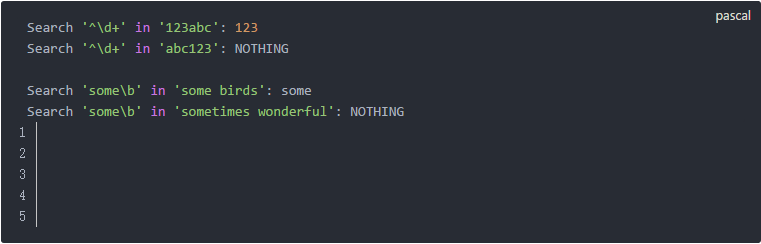
思路:单词的首字母有些会大写,我们可以通过[Rr]来匹配大写或者小写的R字母,但实际上,使用icase无疑会更方便。

这段代码与前面的结构是一样的,我们最需要关注的可能就是下面这一行:

通过std::regex::icase我们指定了这个正则表达式是不区分大小写的。
另外还有一个值得注意的就是正则表达式末尾的...s?,它意味着单词可能是单数或者复数,因此结尾的“s”可以出现0次或者1次。
这段代码输出如下:

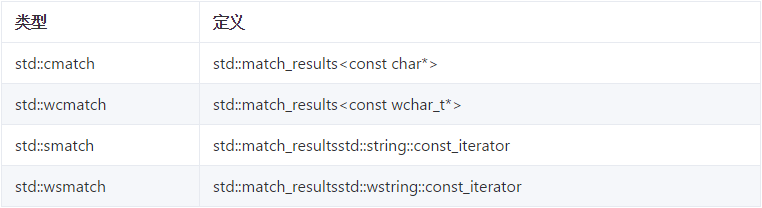
std::match_results用来存储匹配结果。与迭代器类似,匹配结果也有四种类型:
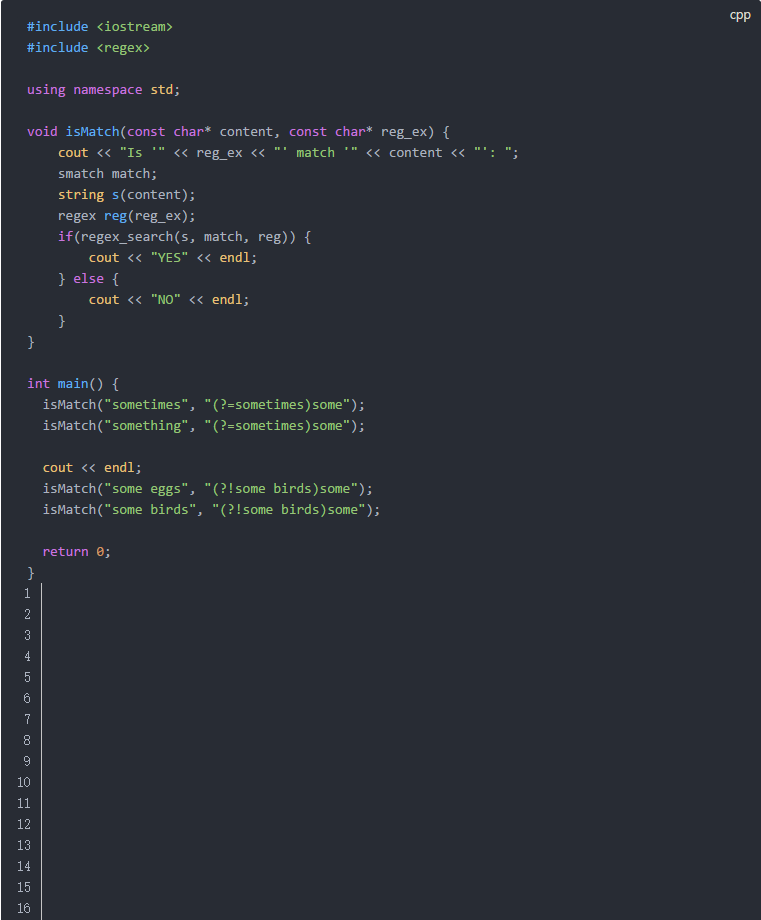
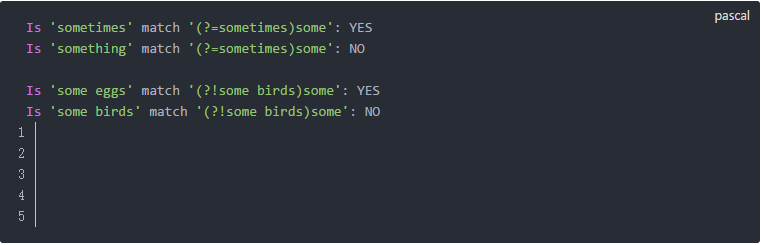
当我们使用正则表达式时,我们的目标常常不单单是判断或者查找完整匹配的内容。而是需要捕获匹配结果中的子串。例如:我们不仅要匹配出日期,还要捕获日期中的年份,月份等信息。这个时候就要使用分组功能。
我们在介绍正则表达式特殊字符的时候,提到过圆括号(和)。它们的作用就是分组。当你在正则表达式中配对的使用圆括号时,就会形成一个分组,一个正则表达式中可以包含多个分组。分组通过编号0, 1, 2, …来区分。编号0的分组是匹配的整体,其他编号根据括号的顺序来确定。
这些分组最终可以在匹配完成之后,可以通过std::match_results的API来获取。这些API如下表所示:

在C++中,分组叫做子匹配(sub_match)。std::sub_match 这个类型只有一个默认构造函数,通常你不会主动创建它,而是使用std::match_results的接口来获取它的对象。
示例:查找出文本中所有的年代,并分离出世纪的部分和年份的部分。 思路:年代的格式是四位数字加上“s”作为后缀。我们可以通过分组的形式分离出两个部分。图示如下:

代码示例:

这段代码说明如下:
sub_match 这段代码输出如下:

热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A
